
Libreria Pandas#
Aprendiendo a programar IV#
Pandas es una biblioteca de análisis de datos en Python que proporciona estructuras de datos flexibles y eficientes para trabajar con datos en formato tabular o estructurado.
Las dos estructuras de datos principales en Pandas son las Series y los DataFrames. Una Serie es una matriz unidimensional etiquetada que puede contener cualquier tipo de datos, mientras que un DataFrame es una estructura de datos bidimensional etiquetada que se compone de una o más Series. Los DataFrames son similares a las tablas en una base de datos y tienen filas y columnas:

Pandas proporciona una amplia variedad de herramientas para manipular y analizar datos, incluyendo:
Selección de datos utilizando índices numéricos o etiquetas de fila y columna.
Operaciones aritméticas y estadísticas en Series y DataFrames.
Fusionar, unir y agrupar datos de múltiples fuentes.
Importación y exportación de datos desde y hacia diferentes formatos, como CSV, Excel y SQL.
Visualización de datos utilizando herramientas integradas o integrando con otras bibliotecas como Matplotlib y Seaborn.
 |
# Importamos las librerías
import pandas as pd
#import matplotlib.pyplot as plt
Series#
Un objeto “Series” es un vector con datos indexados.
pd.Series()
# Esto es una serie
my_series = pd.Series([1, 2, 3, 4, 5])
print(my_series)
0 1
1 2
2 3
3 4
4 5
dtype: int64
Cada miembro de la serie se le asigna un indice. Ya que nosotros no definimos ningún índice, entonces por defecto los índices se asignan de 0 a len(data)-1. En el anterior ejemplo los índices van de 0 a 4.
En el siguiente ejemplo vamos a definir el índice como letras del abecedario:
my_series = pd.Series([1, 2, 3, 4, 5],index=['a', 'b', 'c', 'd','e'])
print(my_series)
a 1
b 2
c 3
d 4
e 5
dtype: int64
Seleccionando datos#
Podemos seleccionar los datos según su posición o su índice
Recuerda que el conteo empienza en 0, por tanto el primer elemento esta guardado en la posición 0
#Primer elemento de la serie por su posición
print( my_series[0])
#por su índice
print(my_series['b'])
1
2
Operaciones entre series#
Con las series podemos realizar operaciones aritméticas, como la suma, la resta, la multiplicación y la división.
# Una suma entre dos series
s1 = pd.Series([1, 2, 3, 4, 5])
s2 = pd.Series([10, 20, 30, 40, 50])
s3 = s1 + s2
print(s3)
0 11
1 22
2 33
3 44
4 55
dtype: int64
# Una resta entre dos series
s3 = s2 - s1
print(s3)
0 9
1 18
2 27
3 36
4 45
dtype: int64
# Multiplicación entre dos series
s3 = s1 * s2
print(s3)
0 10
1 40
2 90
3 160
4 250
dtype: int64
# División entre dos series
s3 = s2 / s1
print(s3)
0 10.0
1 10.0
2 10.0
3 10.0
4 10.0
dtype: float64
Dataframes#
pd.DataFrame()
Imagina que tienes una hoja de cálculo con una fila para cada estudiante en una clase y una columna para su nombre, edad y calificaciones en diferentes asignaturas. Cada fila representa un estudiante y cada columna representa una característica o información sobre ese estudiante. Es una forma ordenada y fácil de leer la información de muchos estudiantes.
Nombre |
Edad |
Matemáticas |
Ciencias |
Historia |
|---|---|---|---|---|
Juan |
12 |
90 |
85 |
95 |
María |
13 |
85 |
90 |
80 |
José |
12 |
80 |
95 |
85 |
Ana |
14 |
95 |
92 |
90 |
Ricardo |
13 |
88 |
85 |
92 |
Del mismo modo, un DataFrame en Pandas es una tabla que puede tener muchas filas y columnas. Cada fila representa una observación o registro, mientras que cada columna representa una variable o característica de esa observación.
# Ahora escribiremos el ejemplo en código
import pandas as pd #importamos la libreria pandas
data = {'Nombre': ['Juan', 'María', 'José', 'Ana', 'Ricardo', 'Laura', 'Diego', 'Marta', 'Carlos', 'Julia', 'Pedro', 'Elena', 'Pablo', 'Carmen', 'Luis', 'Sofía', 'Gabriel', 'Lucía', 'Hugo', 'Mariana'],
'Edad': [12, 13, 12, 14, 13, 15, 12, 14, 13, 15, 14, 13, 12, 14, 13, 12, 14, 15, 13, 14],
'Matemáticas': [90, 85, 80, 95, 88, 92, 78, 85, 89, 91, 83, 90, 87, 85, 88, 82, 79, 91, 84, 86],
'Ciencias': [85, 90, 95, 92, 85, 89, 91, 83, 90, 87, 85, 88, 82, 79, 91, 84, 86, 80, 87, 90],
'Historia': [95, 80, 85, 90, 92, 89, 84, 91, 82, 90, 86, 88, 85, 90, 89, 92, 87, 83, 86, 80]}
df = pd.DataFrame(data)
print(df)
Nombre Edad Matemáticas Ciencias Historia
0 Juan 12 90 85 95
1 María 13 85 90 80
2 José 12 80 95 85
3 Ana 14 95 92 90
4 Ricardo 13 88 85 92
5 Laura 15 92 89 89
6 Diego 12 78 91 84
7 Marta 14 85 83 91
8 Carlos 13 89 90 82
9 Julia 15 91 87 90
10 Pedro 14 83 85 86
11 Elena 13 90 88 88
12 Pablo 12 87 82 85
13 Carmen 14 85 79 90
14 Luis 13 88 91 89
15 Sofía 12 82 84 92
16 Gabriel 14 79 86 87
17 Lucía 15 91 80 83
18 Hugo 13 84 87 86
19 Mariana 14 86 90 80
Pandas tiene funciones muy valiosas que nos facilita el análisis de datos:
Conociendo los datos#
Podemos ver el dataframe así de feo, o simplemente podemos usar el comando
head()
Este comando, es un comando de pandas que nos permitirá visualizar la cabecera del dataframe, también podemos modificarla para ver los últimos registros.
# viendo la cabecera de los datos (5 primeras columnas)
df.head() # Recuerda que df es el nombre que asignamos a nuestro DataFrame
| Nombre | Edad | Matemáticas | Ciencias | Historia | |
|---|---|---|---|---|---|
| 0 | Juan | 12 | 90 | 85 | 95 |
| 1 | María | 13 | 85 | 90 | 80 |
| 2 | José | 12 | 80 | 95 | 85 |
| 3 | Ana | 14 | 95 | 92 | 90 |
| 4 | Ricardo | 13 | 88 | 85 | 92 |
df.head(8) #también df.head() nos muestra el número de filas que indiquemos entre los paréntesis
| Nombre | Edad | Matemáticas | Ciencias | Historia | |
|---|---|---|---|---|---|
| 0 | Juan | 12 | 90 | 85 | 95 |
| 1 | María | 13 | 85 | 90 | 80 |
| 2 | José | 12 | 80 | 95 | 85 |
| 3 | Ana | 14 | 95 | 92 | 90 |
| 4 | Ricardo | 13 | 88 | 85 | 92 |
| 5 | Laura | 15 | 92 | 89 | 89 |
| 6 | Diego | 12 | 78 | 91 | 84 |
| 7 | Marta | 14 | 85 | 83 | 91 |
# o podemos ver la "cola" de los datos con df.tail()
df.tail()
| Nombre | Edad | Matemáticas | Ciencias | Historia | |
|---|---|---|---|---|---|
| 15 | Sofía | 12 | 82 | 84 | 92 |
| 16 | Gabriel | 14 | 79 | 86 | 87 |
| 17 | Lucía | 15 | 91 | 80 | 83 |
| 18 | Hugo | 13 | 84 | 87 | 86 |
| 19 | Mariana | 14 | 86 | 90 | 80 |
# sample toma muestras al azar del dataframe
df.sample()
| Nombre | Edad | Matemáticas | Ciencias | Historia | |
|---|---|---|---|---|---|
| 11 | Elena | 13 | 90 | 88 | 88 |
Un DataFrame contiene columnas de tipo “Series”
type(df["Nombre"])
pandas.core.series.Series
Los datos en los DataFrame pueden tener una vaiedad de tipos. Los tipos principales son: object, float, int, bool y datetime64. Para conocer mejor tus datos, siempre se recomienda conocer el tipo de datos de cada columna:
df.dtypes
Nombre object
Edad int64
Matemáticas int64
Ciencias int64
Historia int64
dtype: object
Para conocer todas las columnas de tu DataFrame, puedes usar:
df.columns()
df.columns
Index(['Nombre', 'Edad', 'Matemáticas', 'Ciencias', 'Historia'], dtype='object')
Para conocer el índice de tu DataFrame, puedes usar:
df.index()
df.index
RangeIndex(start=0, stop=20, step=1)
Manipulando datos:#
Seleccionando columnas:#
Tu puedes seleccionar los datos de una columna indicando su nombre. Por ejemplo, puede seleccionar las dos primeras columnas de la siguiente manera:
dataframe[[' columna 1 ',columna 2']]
df["Edad"]
0 12
1 13
2 12
3 14
4 13
5 15
6 12
7 14
8 13
9 15
10 14
11 13
12 12
13 14
14 13
15 12
16 14
17 15
18 13
19 14
Name: Edad, dtype: int64
Seleccionando filas#
df["Edad"][4]
np.int64(13)
Algunos métodos de Dataframes para obtener información#
info():
Este método te da la cuenta de valores no nulos, el tipo de dato de cada columna (recuerda que solo puede haber un único tipo de dato por columna) y el uso de memoria.
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Nombre 20 non-null object
1 Edad 20 non-null int64
2 Matemáticas 20 non-null int64
3 Ciencias 20 non-null int64
4 Historia 20 non-null int64
dtypes: int64(4), object(1)
memory usage: 928.0+ bytes
#shape retorna las filas y columnas del DataFrame
df.shape
(20, 5)
.shapese usa mucho cuando se limpian o transforman los datos. Por ejemplo, si filtras algunas filas de tu DataFrame, querrás saber cuantas filas fueron eliminadas
# size multiplica las filas y columnas y te da el total de datos del DataFrame.
df.size
100
describe():
Este método te dará un resumen estadístico de las columnas numéricas en el DataFrame, incluyendo el recuento, media, desviación estándar, mínimo, máximo y cuartiles.
# Método describe
df.describe()
| Edad | Matemáticas | Ciencias | Historia | |
|---|---|---|---|---|
| count | 20.00000 | 20.000000 | 20.000000 | 20.000000 |
| mean | 13.35000 | 86.400000 | 86.950000 | 87.200000 |
| std | 1.03999 | 4.558393 | 4.160908 | 4.124382 |
| min | 12.00000 | 78.000000 | 79.000000 | 80.000000 |
| 25% | 12.75000 | 83.750000 | 84.750000 | 84.750000 |
| 50% | 13.00000 | 86.500000 | 87.000000 | 87.500000 |
| 75% | 14.00000 | 90.000000 | 90.000000 | 90.000000 |
| max | 15.00000 | 95.000000 | 95.000000 | 95.000000 |
count: El número de valores no vacios
mean : El promedio de la columna
std : La desviación estandar
min : El valor minimo
25% : El percentil del 25%
50% : El percentil del 50%
75% : El percentil del 75%
max : El valor máximo
En las próximas secciones profundizaremos sobre el concepto de las anteriores definiciones
max():
max(): Este método te dará el valor máximo en cada columna numérica del DataFrame
# Método max. ¿Qué signican cada uno de estos valores?
df.max()
Nombre Sofía
Edad 15
Matemáticas 95
Ciencias 95
Historia 95
dtype: object
min():
Este método te dará el valor mínimo en cada columna numérica del DataFrame.
# Método min
df.min()
Nombre Ana
Edad 12
Matemáticas 78
Ciencias 79
Historia 80
dtype: object
sum():
Este método te dará la suma de cada columna numérica del DataFrame.
# Método sum
df.sum()
Nombre JuanMaríaJoséAnaRicardoLauraDiegoMartaCarlosJu...
Edad 267
Matemáticas 1728
Ciencias 1739
Historia 1744
dtype: object
sort_values():
Este método te permitirá ordenar el DataFrame por los valores de una o más columnas.
# Método sort
df_sorted = df.sort_values(by=['Matemáticas', 'Ciencias'], ascending=False)
print(df_sorted)
Nombre Edad Matemáticas Ciencias Historia
3 Ana 14 95 92 90
5 Laura 15 92 89 89
9 Julia 15 91 87 90
17 Lucía 15 91 80 83
11 Elena 13 90 88 88
0 Juan 12 90 85 95
8 Carlos 13 89 90 82
14 Luis 13 88 91 89
4 Ricardo 13 88 85 92
12 Pablo 12 87 82 85
19 Mariana 14 86 90 80
1 María 13 85 90 80
7 Marta 14 85 83 91
13 Carmen 14 85 79 90
18 Hugo 13 84 87 86
10 Pedro 14 83 85 86
15 Sofía 12 82 84 92
2 José 12 80 95 85
16 Gabriel 14 79 86 87
6 Diego 12 78 91 84
Visualización#
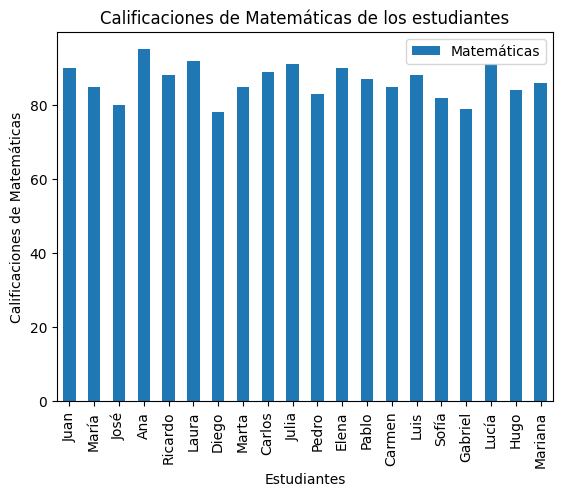
A continuación para ver la importancia de los dataframes, haremos un pequeño análisis para ver las calificaciones de cada estudiante en la materia de matemáticas.
import matplotlib.pyplot as plt #importamos la libreria matplotlib. Esta es la libreria más usada para visualización en Python.
# Crear un gráfico de barras
df.plot(x='Nombre', y='Matemáticas', kind='bar')
# Configurar la apariencia del gráfico
plt.xlabel('Estudiantes')
plt.ylabel('Calificaciones de Matemáticas')
plt.title('Calificaciones de Matemáticas de los estudiantes')
# Mostrar el gráfico
plt.show()
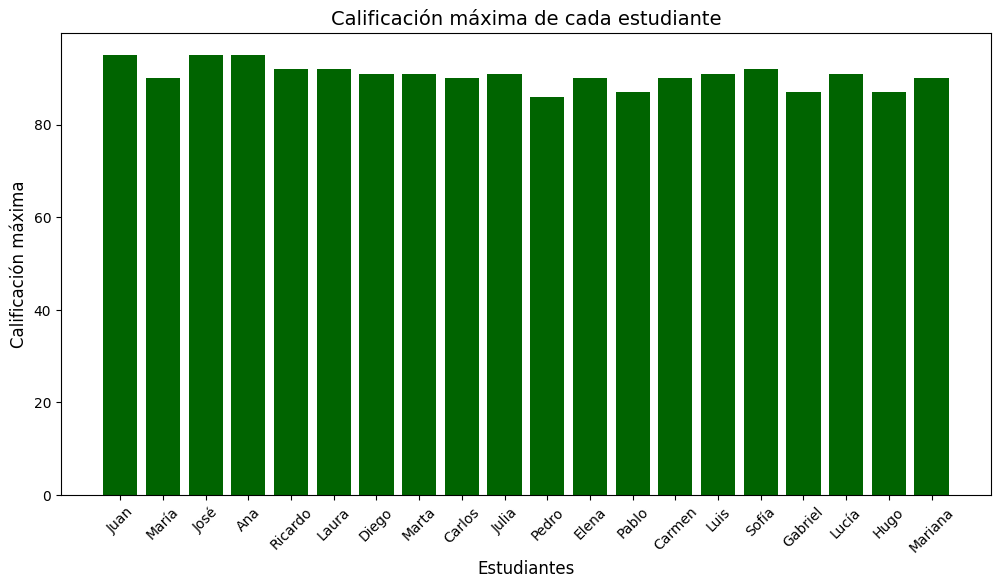
Usando dataframes podemos analizar cualquier cosa de los datos, solo tenemos que ser un poco curiosos, por ejemplo, veremos la calificiación más alta de cada estudiante. Sin importarnos cual materia es.
# Obtener la calificación máxima de cada estudiante
max_scores = df[['Matemáticas', 'Ciencias', 'Historia']].max(axis=1)
# Crear un gráfico de barras con barras de color verde oscuro
plt.bar(df['Nombre'], max_scores, color='darkgreen')
# Configurar la apariencia del gráfico y aumentar el tamaño
plt.xlabel('Estudiantes', fontsize=12)
plt.ylabel('Calificación máxima', fontsize=12)
plt.title('Calificación máxima de cada estudiante', fontsize=14)
plt.xticks(fontsize=10, rotation=45)
plt.yticks(fontsize=10)
plt.gcf().set_size_inches(12, 6)
# Mostrar el gráfico
plt.show()

1. Importar la libreria necesaria
2. Exploren el dataset público que se encuentra en la siguiente url ¿De qué se trata? ¿Cuántas filas tiene? ¿Cuántas columnas?
url = 'https://www.datos.gov.co/api/views/qijw-htwa/rows.csv?accessType=DOWNLOAD'
df = pd.read_csv(url)
3. Mirar las primeras 10 entradas: