
 |
Los datos hablan II#
# importamos las librerias que vamos a usar
import pandas as pd
import numpy as np
from MakeSens import MakeSens
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import warnings
warnings.filterwarnings('ignore')
Estuandiando el material particulado#
Vamos a analizar la variación del de material particulado, \(PM_{1}\), \(PM_{2.5}\) y \(PM_{10}\), a lo largo del día.
Obtención de datos#
Para obtener los datos de material particulado, utilizaremos la función download_data() de la API de MakeSens. Realizaremos el procedimiento usual, es decir, definimos las fechas de inicio y fin en formato “YYYY-MM-DD HH:MM:SS”, el ID de la estación y la frecuencia de muestreo. En este caso, vamos a descargar los datos por hora (h).
#Definimos las fechas de inicio y fin de la descarga de datos (hemos elegido el 29 y 30 de abril)
fecha_inicio = "2023-04-15 00:00:00"
fecha_fin = "2023-05-15 00:00:00"
estacion = "mE1_00004" #Damaso Zapata
frecuencia = "1H"
#Descargar los datos
data = MakeSens.download_data(estacion, fecha_inicio, fecha_fin, frecuencia)
Limpiando datos#
Para que sea un poco más sencillo manejar nuestros datos, definiremos un nuevo DataFrame para almacenar solo con las variables de material particulado. Luego convertiremos el índice de los datos a formato de fecha y hora con la función to_datetime().
#Definimos un nuevo Dataset con las variables que nos interesa
pm_data = data[["pm10_1", "pm10_2","pm25_1", "pm25_2", "pm1_1", "pm1_2"]]
#Indicar mejor la temporalidad
pm_data.index = pd.to_datetime(pm_data.index)
#Exploremos nuestro dataFrame
pm_data.head()
| pm10_1 | pm10_2 | pm25_1 | pm25_2 | pm1_1 | pm1_2 | |
|---|---|---|---|---|---|---|
| 2023-04-15 02:00:00 | 28.666667 | 29.600000 | 26.466667 | 27.066667 | 18.133333 | 17.733333 |
| 2023-04-15 03:00:00 | 31.343750 | 31.468750 | 29.062500 | 29.031250 | 19.593750 | 19.468750 |
| 2023-04-15 04:00:00 | 30.096774 | 32.000000 | 28.225806 | 29.645161 | 19.322581 | 18.935484 |
| 2023-04-15 05:00:00 | 30.733333 | 30.600000 | 28.466667 | 28.500000 | 19.500000 | 19.000000 |
| 2023-04-15 06:00:00 | 28.935484 | 29.064516 | 26.677419 | 26.225806 | 18.000000 | 18.451613 |
Antes de empezar a manipular los datos, debemos preguntarnos:
¿Qué vamos a analizar? ¿Qué queremos saber de los datos? ¿Qué fenómeno queremos estudiar?
Ahora, demos un vistazo a los datos. Veamos, por ejemplo, cómo se comporta el \(PM_{10}\) a lo largo del día.
#Veamos cómo se ven los datos, por el ejemplo veamos Pm10:
plt.figure(figsize=(12, 6))
pm_data.pm10_1.plot(label = 'Sensor 1', marker='.', ls="")
pm_data.pm10_2.plot(label = 'Sensor 2', marker='.', ls="")
#Título y leyenda
plt.title("Datos de PM 10", fontsize=20)
plt.xlabel("Fecha", fontsize=15)
plt.ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
plt.grid(alpha=0.5, linestyle="--")
plt.legend(fontsize=12)
plt.show()
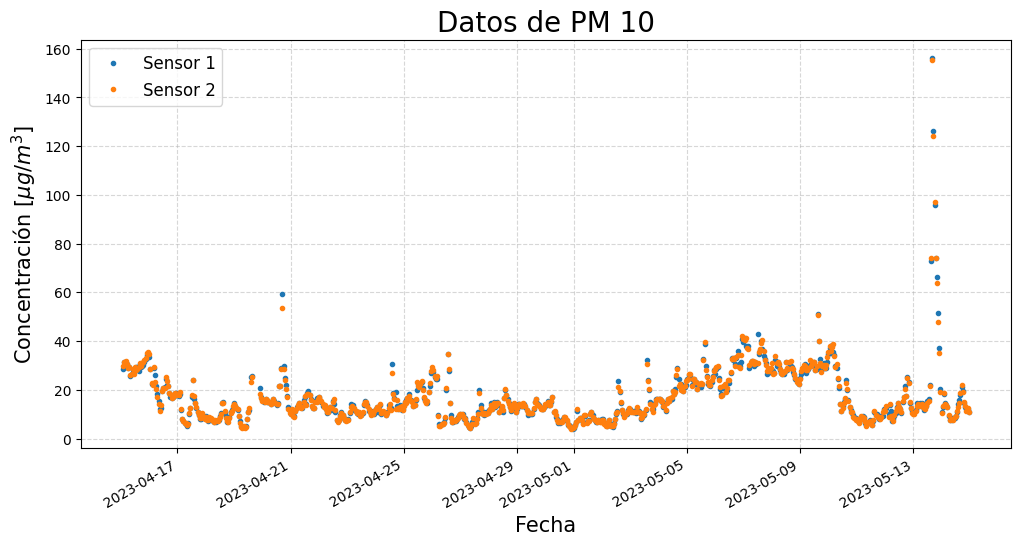
¿Podemos sacar conclusiones con los datos así? ¿Qué piensas que debemos hacer con estos datos, antes de empezar a analizarlos?
Es necesario eliminar los valores excesivamente altos, también llamados datos atípicos o outliers. Estos valores pueden ser causados por errores en los sensores o por eventos extraordinarios, como incendios o eventos climáticos. En este ejemplo, a los valores mayores a 120 les asignamos un valor nulo mediante la función nan. Esto lo haremos con las función .where() de la libreria numpy.
columnas = pm_data.columns #Guardamos los nombres de las columnas en una lista
for columna in columnas: # Iteramos entre cada columna
# Reemplazamos los valores mayores a 120 por NaN
pm_data[columna] = pm_data[columna].where(pm_data[columna]<120, np.nan)
#volvamos a ver cómo se ven los datos:
plt.figure(figsize=(12,6))
pm_data.pm10_1.plot(label = 'Sensor 1', marker='.', ls="")
pm_data.pm10_2.plot(label = 'Sensor 2', marker='.', ls="")
plt.title("Datos de PM 10", fontsize=20)
plt.xlabel("Fecha", fontsize=15)
plt.ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
plt.grid(alpha=0.5, linestyle="--")
plt.legend(fontsize=12)
plt.show()
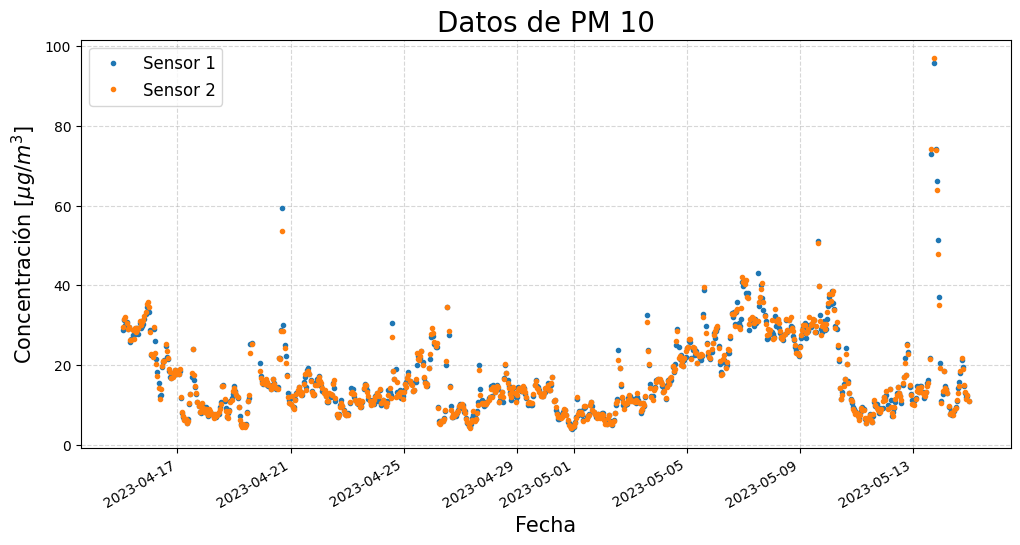
Ya hemos eliminado los datos atípicos, sin embargo, mirando los datos es difícil ver la tendencia. Para arreglar esto, suavicemos las curvas. Debemos realizar un cálculo de la media móvil, esto lo hacemos mediante la funciones .rolling() y .mean() de Pandas.
¿Cómo se calcula la media móvil? La media móvil se calcula como el promedio de los datos en la ventana de tiempo. Por ejemplo, si la ventana de tiempo es de 3 horas, la media móvil en el tiempo \(t\) se calcula como: $\(\frac{PM_{10}(t-1) + PM_{10}(t) + PM_{10}(t+1)}{3}\)$
A diferencia de otros métodos de suavizado, como el promedio, la media móvil nos permite ver la tendencia de los datos, sin perder información sobre los picos y valles. Ahí radica su utilidad e importancia.
La función .rolling() proporciona ventanas deslizantes sobre los datos. En estas ventanas resultantes, podemos realizar cálculos utilizando una función estadística (en este caso, la media). El tamaño de la ventana (número de períodos o cantidad de datos) se puede especificar en el argumento window.
Antes de usar la función
.rolling(), debes tener claro cual es el fenomeno que quieres estudiar y su escala de tiempo típica. Recuerdas que el ancho de la ventana que vas a usar, depende fuertemente de esto.
#Calculemos la media móvil de 24 horas para cada sensor
pm_data['pm10_1_r'] = pm_data['pm10_1'].rolling(window = 24,min_periods=5).mean()
pm_data['pm10_2_r'] = pm_data['pm10_2'].rolling(window = 24,min_periods=5).mean()
pm_data['pm25_1_r'] = pm_data['pm25_1'].rolling(window = 24,min_periods=5).mean()
pm_data['pm25_2_r'] = pm_data['pm25_2'].rolling(window = 24,min_periods=5).mean()
pm_data['pm1_1_r'] = pm_data['pm1_1'].rolling(window = 24,min_periods=5).mean()
pm_data['pm1_2_r'] = pm_data['pm1_2'].rolling(window = 24,min_periods=5).mean()
#Ahora volvamos a graficar nuestros datos
plt.figure(figsize=(12,6))
pm_data.pm10_1_r.plot(label = 'Sensor 1', marker='.', ls="")
pm_data.pm10_2_r.plot(label = 'Sensor 2', marker='.', ls="")
#Agregamos la leyenda y los titulos
plt.title("Datos de PM 10", fontsize=20)
plt.xlabel("Fecha", fontsize=15)
plt.ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
plt.grid(alpha=0.5, linestyle="--")
plt.legend(fontsize=12)
plt.show()
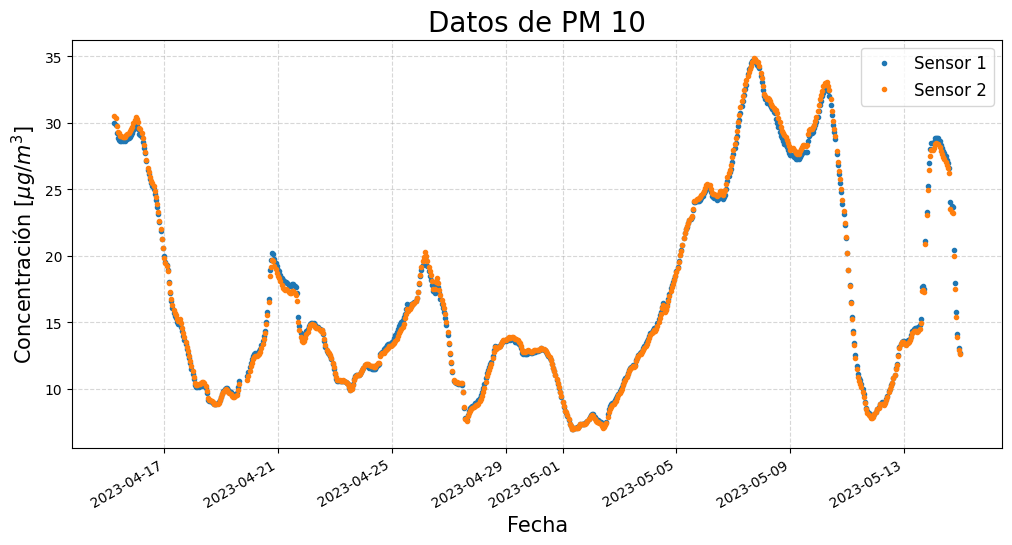
Dado que los datos están registrados por hora, el argumento window=24, que toma 24 datos, corresponde a una ventana de 24 horas. ¿Qué pasa si usamos una ventana de 12 horas? ¿Y si usamos una ventana de 3 horas?
Hemos eliminado los valores atípicos y suavizado los datos. ¿Qué más podemos hacer para mejorar el análisis?
Visualización de datos#
Veamos qué más podemos hacer con los datos. De momento, vamos a promediar los datos utilizando la función .resample() de Pandas. Esta función nos permite agrupar los datos por intervalos de tiempo. En este caso, vamos a agrupar los datos cada 3 días. La diferencia entre .resample() y .rolling() es que .resample() agrupa los datos en intervalos de tiempo, mientras que .rolling() agrupa los datos en ventanas de tiempo.
¿Qué diferencia hay entre agrupar los datos en intervalos de tiempo y agruparlos en ventanas de tiempo?
#Establecer frecuencia
dat = pm_data.resample('3D').mean()
#Calcular desviación estandar
dat2 = pm_data.resample('3D').std()
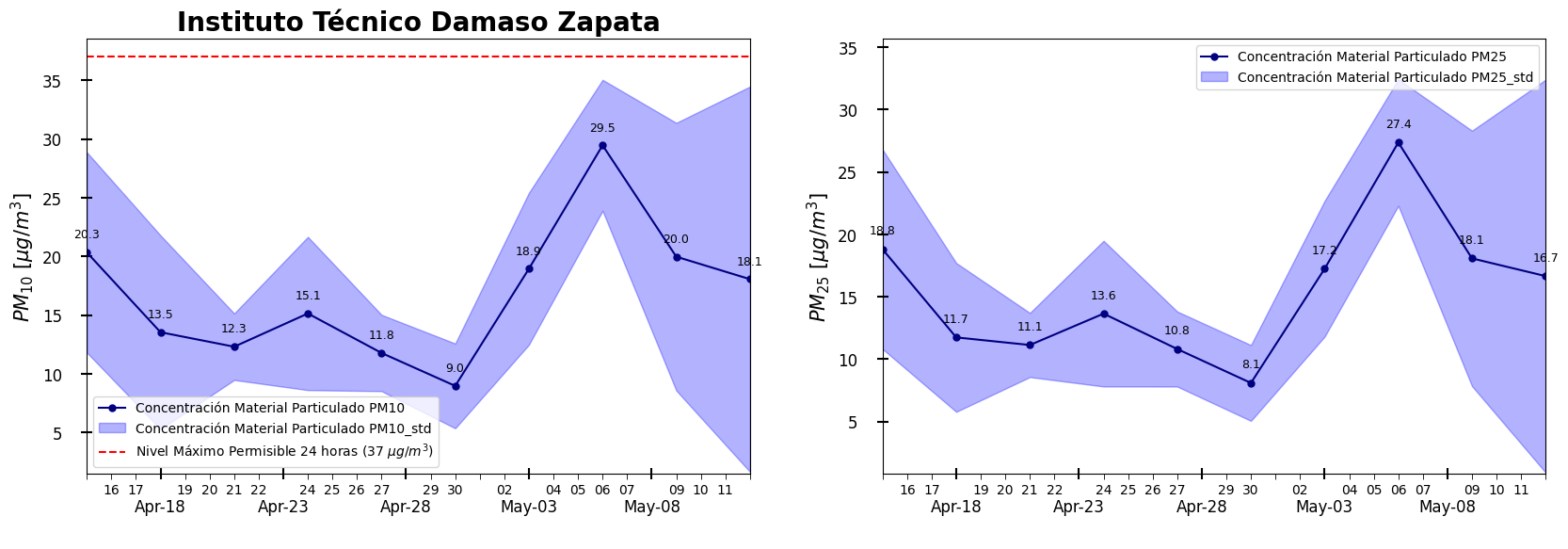
#The recommendation of WHO is 25 μg/m3 daily average, 35 μg/m3 by US EPA, and 50 μg/m3 by Vietname Environmental Administration
fig, ax = plt.subplots(figsize=(15, 5))
# Crear gráfico
dat.pm10_1_r.plot(ax=ax, label='Concentración Material Particulado PM10', marker='o', markersize=8)
plt.fill_between(dat.index, y1 = dat.pm10_1_r-dat2.pm10_1_r, y2 = dat.pm10_1_r + dat2.pm10_1_r, alpha=0.3)
ax.axhline(y=37, color='r', linestyle='--', label='Nivel Máximo Permisible 24 horas (37 $\mu g /m^3$)')
# Añadir etiquetas con valores en cada punto
for x, y in zip(dat.index, dat.pm10_1):
ax.text(x, y+1, f"{y:.1f}", ha="center", va="bottom", fontsize=12, fontweight="bold")
# Añadir leyenda
ax.legend()
# Configurar títulos y etiquetas de los ejes
ax.set_title("Instituto Técnico Damaso Zapata", fontsize=24, fontweight="bold")
#ax.set_xlabel("Tiempo", fontsize=18, fontweight="bold")
ax.set_ylabel("PM10 $[\mu g / m^3]$", fontsize=18, fontweight="bold")
# Configurar límites y escalas de los ejes
ax.set_ylim(0, dat.pm10_1.max() * 1.2)
# Personalizar el formato de las etiquetas del eje x
#ax.xaxis.set_major_formatter(mdates.DateFormatter('%b-%d'))
#ax.xaxis.set_major_locator(mdates.DayLocator(interval=3))
#plt.xticks(rotation=90)
#Formateamos el eje de fechas para que se vea mejor
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b/%d'))
ax.xaxis.set_major_locator(mdates.DayLocator(interval=5))
ax.tick_params(which='major', pad=15, length=8, labelsize=12, direction="inout", width=1.5)
ax.tick_params(which='minor', length=4)
#Pregunta: ¿Por qué aparece esas fechas?
# Mostrar gráfico
plt.show()
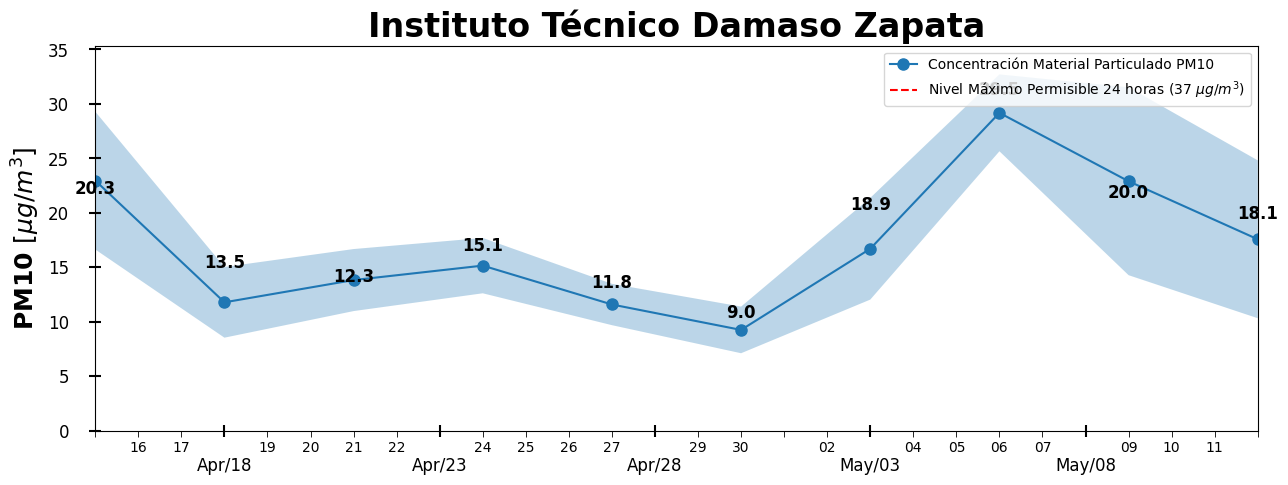
En este ejemplo, hemos graficado la variación del \(PM_{10}\) a lo largo de los días. La zona sombreada hace referencia a la desviación estándar de los datos.
Ahora bien, es importante saber aplicar los conocimientos que hemos adquirido del lenguaje de programación. Para facilitar el trabajo, podemos crear funciones que nos ayuden a realizar tareas repetitivas. En este caso, podemos crear una función que nos permita graficar la variación de los datos a lo largo del día.
#Podemos hacer funciones para reducir el trabajo
def grafica(ax,dat,dat_std,columna,label,titulo,xlabel,ylabel,y_max, color=['blue','red'],alpha=0.5,unit_text=1,locator='day'):
"""
@params
ax : axis
Eje de una figura
dat : dataframe
Set de datos
dat_std : dataframe
Set de datos de desviación estándar
columna : str
Nombre de la columna de datos
label : str
Etiqueta del conjunto de datos
titulo : str
Nombre del título del grafico
xlabel : str
Etiqueta eje x
ylabel : str
Etiqueta eje y
@ejemplo
>> fig, ax = plt.subplots(figsize=(12,6))
>> label = 'Concentración Material Particulado PM2.5'
>> titulo = 'Instituto Técnico Damazo Zapata'
>> xlabel = 'Tiempo'
>> ylabel = 'PM2.5 $[\mu g / m^3]$'
>> grafica(ax, dat, dat_std, 'pm25_1_AE', label, titulo,xlabel,ylabel)
>> plt.show()
"""
## Graficar datos
dat[columna].plot(ax=ax, label=label,marker='o', ms=5,color=color[0])
ax.fill_between(dat.index, dat[columna]+dat_std[columna],dat[columna]-dat_std[columna],alpha=alpha,color=color[1],label=label+'_std')
## Agregar etiquetas a cada punto de datos
for x, y in zip(dat.index, dat[columna]):
ax.text(x, y+unit_text, f"{y:.1f}", ha="center", va="bottom",
fontsize=9#, fontweight="bold"
) #ha: alineamiento horizontal, va: alineamiento vertical
## Configurar título, etiquetas, leyenda y límite del eje 'y'
ax.set_title(titulo, fontsize=20, fontweight="bold") # Titulo
ax.set_xlabel(xlabel, fontsize=15, fontweight="bold") # Etiqueta eje x
ax.set_ylabel(ylabel, fontsize=15, fontweight="bold") # Etiqueta eje y
#ax.set_ylim(-dat[columna].max()*0.3, dat[columna].max() * 1.4) # Límites eje y
## Configurar límites y escalas de los ejes
dat_min = (dat[columna]-dat_std[columna]).min() # Mínimon valor del grafico
dat_max = (dat[columna]+dat_std[columna]).max() # Máximo valor del grafico
if dat_min>0: dat_min*=0.9
else: dat_min*=1.1
ax.set_ylim(dat_min, dat_max*1.1) # Límites eje y
if dat_max*1.1>y_max: #Colocamos la linea horizontal si el valor maximo permisible está dentro del rango de los datos
ax.axhline(y=y_max, color='r', linestyle='--', label="Nivel Máximo Permisible 24 horas ({} $\mu g /m^3$)".format(y_max)) # Línea horizontal
ax.legend() # Leyenda
## Convertir las fechas de las etiquetas del eje x a formato Mes-día
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b-%d'))
if locator=='day':
ax.xaxis.set_major_locator(mdates.DayLocator(interval=5))
if locator=='month':
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=2))
ax.tick_params(which='major', pad=15, length=8, labelsize=12, direction="inout", width=1.5)
ax.tick_params(which='minor', length=4)
Una vez hemos creado nuestra función, podemos utilizarla para graficar la variación de los datos de \(PM_{1}\), \(PM_{2.5}\) y \(PM_{10}\) a lo largo del mes.
# Probemos la función que hemos creado
fig = plt.subplots(figsize=(20,6))
ax = plt.subplot(121)
label = 'Concentración Material Particulado PM10'
titulo = 'Instituto Técnico Damaso Zapata'
xlabel = ' '
ylabel = '$PM_{10} ~ [\mu g / m^3]$'
alpha=0.3
color=["navy", "Blue"]
y_max = 37
grafica(ax, dat, dat2,'pm10_1', label, titulo,xlabel,ylabel, y_max, color,alpha)
#grafica(ax, dat, dat2,'pm10_1_AE', label, titulo,xlabel,ylabel)
ax = plt.subplot(122)
titulo = ' '
label = 'Concentración Material Particulado PM25'
ylabel = '$PM_{25}~[\mu g / m^3]$'
y_max = 37
grafica(ax, dat, dat2,'pm25_1', label, titulo,xlabel,ylabel, y_max, color,alpha)
# ax.axhline(y=37, color='r', linestyle='--', label="Nivel Máximo Permisible 24 horas (37 $\mu g /m^3$")
#grafica(ax, dat, dat2,'pm10_1_AE', label, titulo,xlabel,ylabel)
plt.show()
Sub-gráficas#
Tenemos tres tipos de material particulado, cada uno de ellos medidos con dos sensores. Para empezar a procesar los datos, primero debemos saber si los dos sensores de cada tipo de material particulado miden lo mismo. Para esto, realizaremos un promedio entre dichas medidas para obtener un único valor de material particulado por cada medición. Para esto, utilizaremos las funciones .mean() y .resample() de Pandas. Trabajaremos sobre los datos ya limpios y suavizados.
# Sacamos un promedio de los datos de los sensores para cada tipo de partícula
pm_data_mean = pd.DataFrame()
pm_data_mean["PM_1"] = pm_data[["pm1_1_r", "pm1_2_r"]].mean(axis=1)
pm_data_mean["PM_25"] = pm_data[["pm25_1_r", "pm25_2_r"]].mean(axis=1)
pm_data_mean["PM_10"] = pm_data[["pm10_1_r", "pm10_2_r"]].mean(axis=1)
Vamos a crear una gráfica compuesta de 4 subgráficas, una para cada tipo de material particulado y una última donde se muestren los datos de los 3 tipos de material particulado. Para esto, utilizaremos la función .subplots() de Matplotlibs. Luego, estableceremos el estilo de la gráfica, en este caso “default” (por defecto). A continuación, graficaremos diferentes series de datos de material particulado, incluyendo el material particulado promedio por hora, por día y el material particulado registrado por cada sensor. Además, rellenaremos el área entre los dos sensores de datos.
¿Qué pasa si cambiamos el estilo de la gráfica? Puedes conocer cuáles estilos están disponibles revisando en la documentación.
#Creamos una figura con 4 subplots
fig, ax = plt.subplots(2, 2, figsize=(15, 10))
#Dejamos un poco más de espacio entre los subplots
fig.subplots_adjust(hspace=0.4)
#Graficamos los datos de PM 1
ax[0,0].plot(pm_data.pm1_1_r, label="Sensor 1", alpha=0.5, color="green")
ax[0,0].plot(pm_data.pm1_2_r, label="Sensor 2", alpha=0.5, color="blue")
ax[0,0].plot(pm_data_mean.PM_1, label="Promedio", alpha=0.8, color="red", linestyle="--")
ax[0,0].fill_between(pm_data.index, pm_data.pm1_1_r, pm_data.pm1_2_r, alpha=0.3)
#Agregamos la leyenda y los titulos
ax[0,0].set_title(r"$PM_{1}$ - Abril 29 y 30", fontsize=20)
ax[0,0].set_ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
ax[0,0].set_xlabel("Fecha", fontsize=15)
ax[0,0].grid(alpha=0.5, linestyle="--")
ax[0,0].legend(fontsize=12)
#Graficamos los datos de PM 2.5
ax[0,1].plot(pm_data.pm25_1_r, label="Sensor 1", alpha=0.5, color="green")
ax[0,1].plot(pm_data.pm25_2_r, label="Sensor 2", alpha=0.5, color="blue")
ax[0,1].plot(pm_data_mean.PM_25, label="Promedio", alpha=0.8, color="red", linestyle="--")
ax[0,1].fill_between(pm_data.index, pm_data.pm25_1_r, pm_data.pm25_2_r, alpha=0.3)
#Agregamos la leyenda y los titulos
ax[0,1].set_title(r"$PM_{2.5}$ - Abril 29 y 30", fontsize=20)
ax[0,1].set_ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
ax[0,1].set_xlabel("Fecha", fontsize=15)
ax[0,1].grid(alpha=0.5, linestyle="--")
ax[0,1].legend(fontsize=12)
#Graficamos los datos de PM 10
ax[1,0].plot(pm_data.pm10_1_r, label="Sensor 1", alpha=0.5, color="green")
ax[1,0].plot(pm_data.pm10_2_r, label="Sensor 2", alpha=0.5, color="blue")
ax[1,0].plot(pm_data_mean.PM_10, label="Promedio", alpha=0.8, color="red", linestyle="--")
ax[1,0].fill_between(pm_data.index, pm_data.pm10_1_r, pm_data.pm10_2_r, alpha=0.3)
#Agregamos la leyenda y los titulos
ax[1,0].set_title(r"$PM_{10}$ - Abril 29 y 30", fontsize=20)
ax[1,0].set_ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
ax[1,0].set_xlabel("Fecha", fontsize=15)
ax[1,0].grid(alpha=0.5, linestyle="--")
ax[1,0].legend(fontsize=12)
#Graficamos los promedios de los datos de PM 1, 2.5 y 10
ax[1,1].plot(pm_data_mean.PM_1, label=r"$PM_{1}$", alpha=0.8, color="green", linestyle="--")
ax[1,1].plot(pm_data_mean.PM_25, label=r"$PM_{2.5}$", alpha=0.8, color="blue", linestyle="--")
ax[1,1].plot(pm_data_mean.PM_10, label=r"$PM_{10}$", alpha=0.8, color="red" , linestyle="--")
#Agregamos la leyenda y los titulos
ax[1,1].set_title(r"Promedio $PM_{1}$, $PM_{2.5}$ y $PM_{10}$ - Abril 29 y 30", fontsize=20)
ax[1,1].set_ylabel(r"Concentración [$\mu g/m^3$]", fontsize=15)
ax[1,1].set_xlabel("Fecha", fontsize=15)
ax[1,1].grid(alpha=0.5, linestyle="--")
ax[1,1].legend(fontsize=12)
#Formateamos el eje de las fechas para los 4 subplots
for i in range(2):
for j in range(2):
ax[i,j].xaxis.set_major_formatter(mdates.DateFormatter('%b/%d'))
ax[i,j].xaxis.set_major_locator(mdates.DayLocator(interval=5))
#ax[i,j].xaxis.set_major_locator(mdates.HourLocator(byhour=range(0,24,6)))
#ax[i,j].tick_params(which='major', pad=15, length=8, labelsize=12, direction="inout", width=1.5)
#ax[i,j].tick_params(which='minor', length=4)
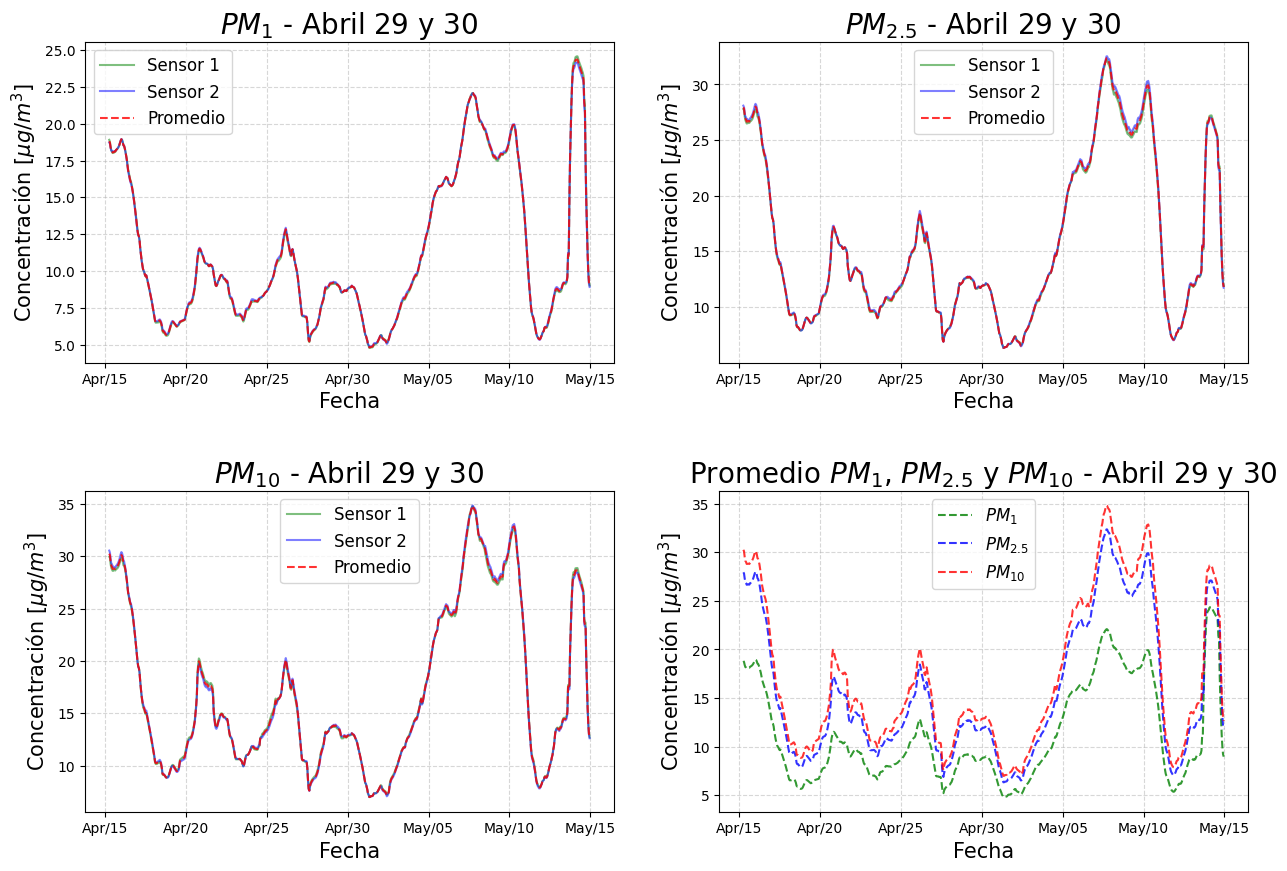
Ahora que tenemos nociones de cómo se comporta el material particulado, surgen ciertas preguntas:
¿Por qué el \(PM_{1}\) es menor que el \(PM_{2.5}\) y el \(PM_{10}\)?
¿Qué pasa con el material particulado en la noche?
¿Se comportará igual durante todo el mes o solo se trata de un caso particular?
Procedamos a realizar un análisis de los datos de material particulado por día de la semana:
¿La concentración de material particulado cambia los fines de semana?#
Vamos a comparar la concentración de material particulado \(PM_{2.5}\), durante los días de semana (lunes a viernes) con los fines de semana (sábado y domingo). Antes de empezar, es crucial tomarnos un tiempo para pensar en el problema que queremos resolver y el resultado que esperamos obtener para así tener una nocion de lo que estamos haciendo. Por ejemplo, ¿Esperamos que la concentración de material particulado aumente o disminuya los fines de semana?
Vistazo rápido a los datos#
Usemos la función .dayofweek de Pandas para obtener el día de la semana de cada medición. Luego, usando la función .scatter() de Matplotlib, grafiquemos la concentración de material particulado \(PM_{2.5}\) en función del día de la semana. ¿Qué observamos?
# Demos una vista rápida de como se agrupan nuestro datos para cada día de la semana.
#Ten en cuenta que 0:Lunes y 6:Domingo.
plt.scatter( pm_data.index.dayofweek, pm_data.pm25_1)
plt.xticks(range(7), ["Lunes", "Martes", "Miércoles", "Jueves", "Viernes", "Sábado", "Domingo"], fontsize=12)
plt.ylabel(r"Concentración PM_2.5 [$\mu g/m^3$]", fontsize=15)
plt.xlabel(r"Día de la semana", fontsize=15)
plt.show()
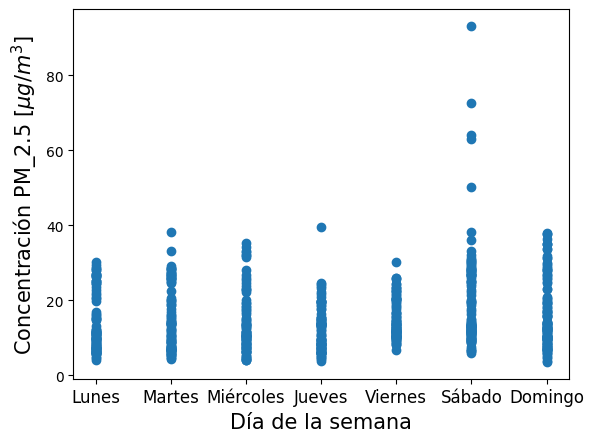
Podemos ver que la mayoría de los datos mantienen una concentración menor a \(40 \mu g/m^3\). Sin embargo, hay algunos datos que superan los \(60 \mu g/m^3\). Sabemos que no son datos atípicos dado que ya los habíamos eliminado, ¿A qué se deben? ¿Qué pasa con los datos de los fines de semana? ¿Son mayores o menores que los de los días de semana? Para sacar una conclusión más profunda, debemos realizar un análisis estadístico de los datos.
Análisis estadístico#
Ya que estamos interesados en comparar la concentración de PM\(_{2.5}\) entre días de la semana, vamos a trabajar con el promedio para cada día.
dfd = pm_data.resample('1D').mean()
dfd.head()
| pm10_1 | pm10_2 | pm25_1 | pm25_2 | pm1_1 | pm1_2 | pm10_1_r | pm10_2_r | pm25_1_r | pm25_2_r | pm1_1_r | pm1_2_r | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023-04-15 | 29.670436 | 30.217762 | 27.583211 | 28.082131 | 18.826244 | 18.878597 | 29.042474 | 29.460265 | 26.930521 | 27.279859 | 18.350135 | 18.359299 |
| 2023-04-16 | 20.617540 | 20.559732 | 19.042636 | 19.075604 | 13.195091 | 13.057339 | 26.000077 | 26.231575 | 24.113571 | 24.403532 | 16.557703 | 16.480267 |
| 2023-04-17 | 11.510032 | 11.712208 | 10.517173 | 10.635060 | 7.402916 | 7.465217 | 15.360884 | 15.500033 | 14.159985 | 14.277592 | 9.900639 | 9.912060 |
| 2023-04-18 | 9.185306 | 9.144166 | 8.216076 | 8.246498 | 5.868910 | 5.995632 | 9.700674 | 9.801083 | 8.766365 | 8.822794 | 6.181236 | 6.301270 |
| 2023-04-19 | 11.806352 | 11.437928 | 9.961896 | 10.047927 | 6.983744 | 7.066135 | 9.975421 | 9.823073 | 8.869834 | 8.865506 | 6.393525 | 6.459632 |
Vamos a dividir nuestro DataFrame en varios DataFrame, cada uno para una semana diferente. Para esto, usaremos el método de python isocalendar(), el cual devuleve el año, número de la semana y día. Para saber más, puedes visitar la página de documentación de pandas.
#Separemos el Dataframe en varios por semanas
dfw = [ g for _,g in dfd.groupby(dfd.index.isocalendar().week)]
dfw[2].head()
| pm10_1 | pm10_2 | pm25_1 | pm25_2 | pm1_1 | pm1_2 | pm10_1_r | pm10_2_r | pm25_1_r | pm25_2_r | pm1_1_r | pm1_2_r | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2023-04-24 | 13.483311 | 13.217195 | 11.717640 | 11.920113 | 8.595310 | 8.578512 | 12.252821 | 12.236541 | 10.978927 | 11.144935 | 8.101904 | 8.166043 |
| 2023-04-25 | 17.886180 | 17.929132 | 16.290635 | 16.448710 | 11.519626 | 11.712691 | 15.570929 | 15.288301 | 13.847394 | 13.932275 | 9.958938 | 10.054332 |
| 2023-04-26 | 14.050167 | 14.274130 | 12.930881 | 13.042830 | 9.049019 | 9.097472 | 17.628713 | 17.904329 | 16.148860 | 16.398247 | 11.248959 | 11.358491 |
| 2023-04-27 | 8.961057 | 8.761688 | 8.101100 | 8.052033 | 6.011335 | 6.053539 | 9.806977 | 9.789026 | 8.932799 | 8.945129 | 6.498891 | 6.563769 |
| 2023-04-28 | 13.618552 | 13.654684 | 12.541768 | 12.569652 | 9.097508 | 9.210844 | 11.741869 | 11.577958 | 10.719814 | 10.676836 | 7.835150 | 7.910883 |
Definimos una función que nos devuelva el valor de la razón del promedio de la concentración de material particulado entre los días de semana y los fines de semana. Esto es, el promedio de la concentración de material particulado los fines de semana dividido por el promedio de la concentración de material particulado los días de semana.
def cal_ratio_week(data):
#El argumento de esta funcion será un dataFrame llamado data
week_ends = [5,6] #Los fines de semana son los numeros 5(Sabado) y 6(domingo)
#Dividimos los datos entre fines de semana, y dias de semana. Primero los agrupamos por el día de la semana y luego los filtramos si son fines de semana o no.
weekdays = data.groupby(data.index.dayofweek).filter(lambda ele: ele.index.dayofweek not in week_ends)
weekends = data.groupby(data.index.dayofweek).filter(lambda ele: ele.index.dayofweek in week_ends)
date_ = data.index[-1] # tomamos la fecha del último dato de DataFrame data. Los más probables es que esta fecha corresponda a un Domingo
#Tomamos la razon si en nuestro datos hay al menos dos dias en los dias entre semana y un dia en el fin de semana
if weekdays.isnull().sum().pm25_1 <2 and weekends.isnull().sum().pm25_1 <1:
ratio = weekends.mean()/weekdays.mean()
output = {'date': date_, 'ratio': ratio.pm25_1} #utilizamos el valor de la variable date_ como indice de la razon
else:
output = {'date': date_, 'ratio': 0}
return output
Hemos creado una función llamada cal_ratio_week() que toma un set de datos como argumento. Lo primero que hace la función es dividir el DataFrame de entrada en dos partes: una para los días de semana (Weekdays) y otra para los fines de semana (Weekends). Esto lo hace utilizando la función .groupby() y la función .filter(). Posteriormente calculamos la razón (ratio) entre los fines de semana y los días de semana siempre, siempre y cuando haya por lo menos 2 días entre semana y 1 día de fin de semana. Finalmente, la función devuelve el ratio calculado y la fecha de la semana correspondiente en forma de diccionario.
Ahora podemos aplicar nuestra función a todos los DataFrame que formamos anteriormente. Podemos crear un nuevo set de datos que contenga los ratios calculados para cada semana:
# aplicamos la funcion cal_ratio_week() a todos los DataFrame que formamos con nuestros datos originales
week_ratios = list() #Creamos una lista vacia
for i, data in enumerate(dfw):
#Agregamos los datos de la funcion cal_ratio_week() a la lista week_ratios
week_ratios.append(cal_ratio_week(data))
#Formamos un nuevo DataFrame con las razones que hemos calculado (week_ratios)
dfrw = pd.DataFrame.from_dict(week_ratios) #Formamos un DataFrame con los datos de week_ratios
dfrw.head()
| date | ratio | |
|---|---|---|
| 0 | 2023-04-16 | NaN |
| 1 | 2023-04-23 | 0.893206 |
| 2 | 2023-04-30 | 0.829644 |
| 3 | 2023-05-07 | 2.090374 |
| 4 | 2023-05-14 | 1.049021 |
Acá hemos utilizado la función .append() de Pandas para agregar los ratios calculados a la lista creada. Luego, hemos creado un nuevo DataFrame con los ratios calculados.
¿Por qué obtuvimos
NaNen la primera entrada?
Ahora podemos visualizar los datos obtenidos:
#Ahora vizualicemos los datos
fig, ax = plt.subplots(figsize=(10, 5))
dfrw2 = dfrw.query('ratio!=0') #Filtramos los datos que no son cero
ax.set_title("Razón de concentración de $PM_{25}$ entre fin de semana y entre semana", fontsize=20)
ax.set_xlabel("Fecha", fontsize=15)
ax.set_ylabel("Razón $PM_{2.5}$", fontsize=15)
#dfrw2['ratio'].plot()
ax.plot( dfrw2.date, dfrw2.ratio, "-", marker="o", markersize=3)
ax.grid(alpha=0.5, linestyle="--")
#Podemos formatear el eje de las fechas para que se vea mejor
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b/%d'))
ax.xaxis.set_major_locator(mdates.DayLocator(interval=5))
plt.show()
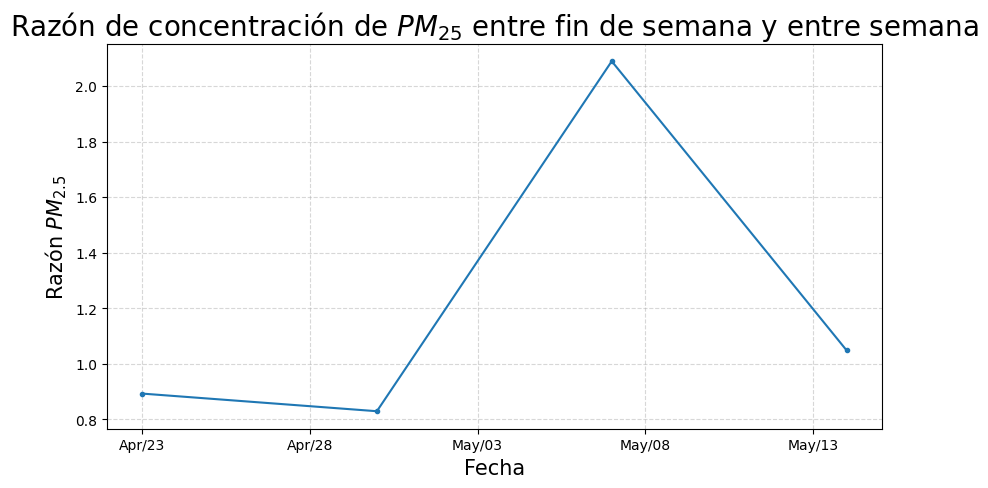
¿Que representa un valor mayor que uno? ¿Un valor menor que uno?
Puedes explicar el resultado ¿Obtuviste lo que esperabas?
Gráfica de bigotes#
Finalmente, vamos a graficar los datos obtenidos utilizando la función .boxplot() de Pandas. Esta función nos permite visualizar la distribución de los datos. En este caso, vamos a graficar la distribución de los ratios calculados para cada semana.
Por otra parte, ya hemos trabajado los cuartiles. Un cuartil es un valor que divide un conjunto de datos en cuatro partes iguales. Los cuartiles se pueden calcular utilizando la función .quantile() de Pandas. Por ejemplo, el primer cuartil es el primer conjunto de datos tras efectuar la división. Es decir, el 25% de los datos se encuentran por debajo del primer cuartil mientras que el 75% de los datos se encuentran por encima del primer cuartil.
#Analicemos nuetro resultado con una gráfica de bigotes
plt.figure(figsize=(8,5))
#Eliminamos los datos que son cero
dfrw2 =dfrw2.dropna()
#Iniciamos la gráfica de bigotes
plt.boxplot(x = dfrw2['ratio'].values,
vert=False,
#meanline=True, showmeans=True,
)
plt.xlabel("PM25 (fin de semana)/ PM25 (entre-semana)")
plt.title("Razón de concentración de $PM_{25}$ entre fin de semana y entre semana", fontsize=20)
ax = plt.gca()
ax.set_yticklabels(['Damaso'])
# plt.annotate(s_text, xy=(0.8, 0.8), xycoords="data", bbox=bbox_props, size=13, ha="left", va="center");
plt.tight_layout()
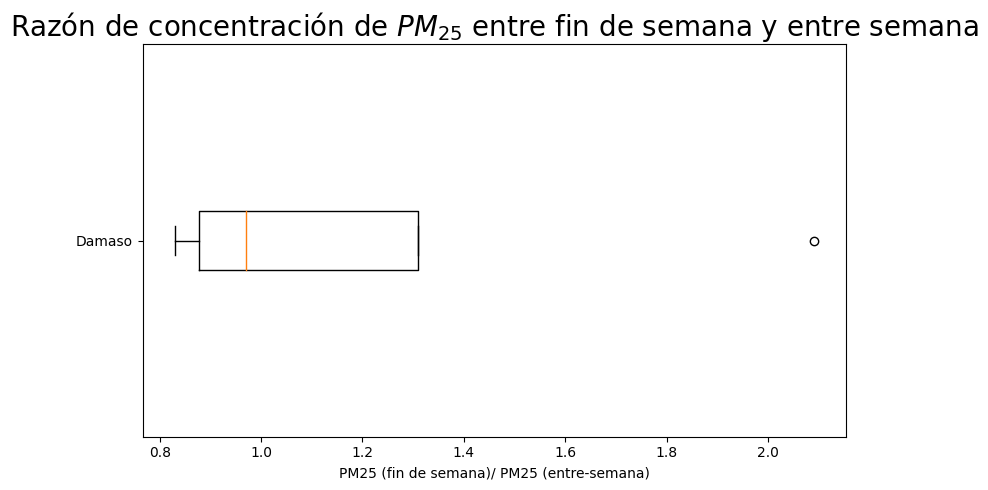
¿Qué conclusiones tenemos de este gráfico?
Indice de Calidad de Aire#
Hemos visto que las estaciones cuentan el número de partículas presentes en el aire y a partir de allí se determina la concentración de cada una de ellas. Sin embargo, no todas las partículas son iguales, algunas son más dañinas que otras. Por ejemplo, las partículas de menos de 2.5 micrómetros de diámetro son las más dañinas para la salud humana, ya que pueden penetrar profundamente en los pulmones y causar problemas respiratorios. Por otro lado, las partículas de menos de 10 micrómetros de diámetro pueden penetrar en los pulmones y causar problemas respiratorios y cardiovasculares. Además, una concentración no nos dice mucho respecto a qué tan dañado está el aire que respiramos.
Es por esto que surge la necesidad de establecer un Índice de Calidad de Aire (ICA) que nos permita conocer el estado del aire que respiramos. Este índice es un valor representativo de los índices de contaminación más significativos. Así, es posible clasificar la calidad del aire en seis categorías, cada una de ellas asociada a un color y a un valor del ICA, tal como vimos en la tabla de la sección calidad del aire.
La fórmula para calcular el ICA es la siguiente:
\( {ICA}_{p} = \frac{I_{alto}-I_{bajo}}{PC_{alto}-PC_{bajo}}\times (C_{p}-PC_{bajo})+I_{bajo} , \)
donde:
\({ICA}_{p}\) es el índice de calidad del aire para el contaminante \(p\).
\({C_{p}}\) es la concentración del contaminante \(p\).
\({PC_{bajo}}\) es el punto de corte menor o igual a \(C_{p}\).
\({PC_{alto}}\) es el punto de corte mayor o igual a \(C_{p}\).
\({I_{bajo}}\) es el índice correspondiente al punto de corte \({PC_{bajo}}\).
\({I_{alto}}\) es el índice correspondiente al punto de corte \({PC_{alto}}\).
Todos estos valores se pueden encontrar en la página del IDEAM.